





Lazy Evaluation 지연 계산법
들어가며
Lazy Evaluation은 예전에 조건문에서 두 개의 조건이 존재할 때 AND에서는 앞 조건이 False라고 하는 경우 뒤 조건을 안하는 경우를 Early Termination이라고 들은 적이 있었습니다. 그 때 비슷한 최적화의 형태로 Lazy Evaluation가 있다고 들었었는데요.
뭔가 다른 건가 싶기도 했었습니다. 한참 데이터 쪽으로 공부하고 있을 때 spark에 대해서 공부한 적이 있었는데요. spark는 Lazy Evaluation을 지원해서 좋다고 합니다. 아니 그래서 뭐가 좋은건지도 모르지 말고 이번에는 공부하면서 블로그에 정리하려고 합니다. 역시 공부는 호기심
참고:
Lazy Evaluation 정의
그림 동작 및 예제 : edykim님 블로그
Lazy Evaluation
컴퓨터 프로그래밍에서 느긋한 계산법(Lazy Evaluation)은 계산의 결과값이 필요할 때까지 계산을 늦추는 기법입니다. 반대말로는 Eager Evaluation(즉시 연산, 조급한 연산)이 존재합니다.
먼저 장단점을 알면 편하므로 장단점을 정리해보겠습니다.
장점
- 효율성: 필요한 값만 계산하므로 불필요한 연산을 피할 수 있습니다. 예를 들어, 무한한 리스트에서 처음 10개의 요소만 필요한 경우, lazy evaluation을 사용하면 실제로 10개의 요소만 계산됩니다.
- 모듈화와 조합성: 계산을 나중에 실행하게 되면, 프로그램의 여러 부분을 더 쉽게 조합하거나 재사용할 수 있습니다.
- 무한한 자료구조: Lazy evaluation을 사용하면 무한한 크기의 자료구조를 생성하고, 필요한 부분만 사용할 수 있습니다. 예를 들어, Haskell(프로그래밍 언어)에서 무한한 리스트를 정의하고 사용할 수 있습니다.
- 가능한 결과 생성: Lazy evaluation은 아직 계산되지 않은 결과를 표현할 수 있어, 연산의 가능한 결과를 모두 나열하고 나중에 특정 결과를 선택할 수 있습니다.
단점
- 예측하기 어려운 성능: 연산이 언제 실행될지 예측하기가 어렵기 때문에, 프로그램의 성능을 예측하거나 분석하기가 어려울 수 있습니다.
- 메모리 사용: 연산이 아직 실행되지 않았다는 것을 표시하기 위한 내부 데이터 구조가 추가적인 메모리를 사용할 수 있습니다. 이로 인해 메모리 사용이 증가할 수 있습니다.
- 디버깅 어려움: Lazy evaluation의 동작 방식 때문에, 오류를 디버깅하기가 어려울 수 있습니다. 오류의 원인이 되는 코드와 오류가 실제로 발생하는 시점 사이에 시간 차이가 있을 수 있기 때문입니다.
- 부작용: 부작용(side-effects)를 가진 연산과 lazy evaluation이 혼합될 때, 부작용의 발생 시점과 순서를 예측하기 어려울 수 있습니다.
이렇게 장단점을 알아봤습니다. 그런데 이 장점 중 왜 효율적일까, 무한한 자료구조는 어떻게 하는 걸까에 대해서 중점적으로 알아보겠습니다.
Lazy Evaluation은 어떻게 효율적으로 동작하는걸까
자바 예제부터 보겠습니다. 아래의 자바 코드는 정수의 List에서 10보다 작은 것 중 3개만 가져오는 코드입니다.
final List<Integer> list = Arrays.asList(4, 15, 20, 7, 3, 13, 2, 20);
System.out.println(
list.stream()
.filter(i -> {
return i < 10;
})
.limit(3)
.collect(Collectors.toList())
);모르는 사람이 처음 위의 코드를 접했을 때 위 코드 동작 방식을
- 반복을 통해 Array에서 요소들 중 10보다 작은 값을 구하고
- 그 중 3개만 가져옵니다.
라고 생각할 수 있지만 그렇지 않습니다.
그렇지 동작하지 않는 이유를 알기 위해 출력해보겠습니다.
final List<Integer> list = Arrays.asList(4, 15, 20, 7, 3, 13, 2, 20);
System.out.println(
list.stream()
.filter(i -> {
System.out.println("i: " + i + " < 10");
return i < 10;
})
.limit(3)
.collect(Collectors.toList())
);i: 4 < 10
i: 15 < 10
i: 20 < 10
i: 7 < 10
i: 3 < 10
[4, 7, 3]위는 출력해본 결과입니다! 이를 통해 조건에 맞는 것을 찾으면 종료한다는 것을 알 수 있습니다.
이 동작을 그림으로 표현한 것이 있어서 가져왔습니다.
출처는 맨 위에 있습니다.
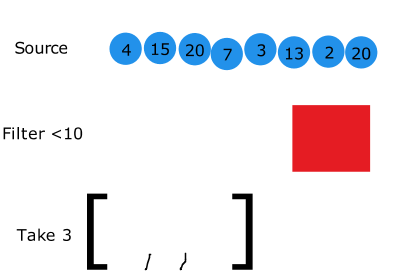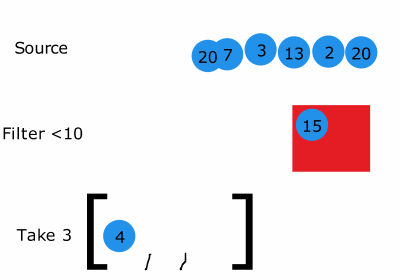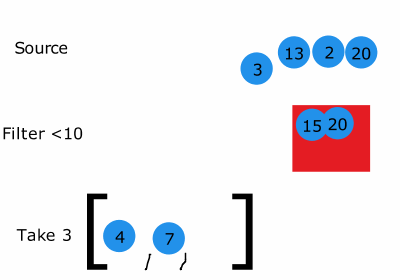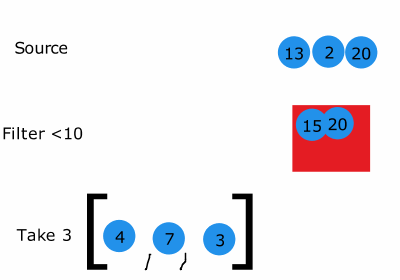
위 코드를 그림으로 나타낸것입니다.
그림을 보면 출력 결과와 같이 동작한다는 것을 알 수 있습니다.
어찌보면 3개를 취했을 때 반복문이 종료되므로 더 효율적으로 종료될 수 있는 것입니다!
이를 메모리 관점에서는 동작이 다르겠지만 로직 처리쪽으로만 본다면 아래의 코드처럼 나타낼 수 있습니다.
final List<Integer> list = Arrays.asList(4, 15, 20, 7, 3, 13, 2, 20);
final List<Integer> newList = new ArrayList<>();
for (int i = 0; i < list.size(); i++) {
System.out.println("list[i]: " + list.get(i) + " < 10");
if (list.get(i) < 10) {
newList.add(list.get(i));
if (newList.size() == 3) break;
}
}
System.out.println(newList);출력결과
list[i]: 4 < 10
list[i]: 15 < 10
list[i]: 20 < 10
list[i]: 7 < 10
list[i]: 3 < 10
[4, 7, 3]
출력결과를 보면 동일한 것을 알 수 있습니다.
Lazy Evaluation을 통해 조건을 만족하면 반복문이 종료되는 것을 알 수 있습니다.
이를 통해 효율성을 챙기는 것입니다.
그럼 이번에는 메모리 관점으로 어떻게 무한한 자료구조를 쓸 수 있는지 보겠습니다.
Lazy Evaluation은 어떻게 무한한 자료구조를 만들 수 있을까?
아래는 파이썬의 제너레이터로 작성한 자료구조와 리스트 컴프리헨션으로 만든 리스트의 메모리를 비교한 것입니다.
import sys
# 제너레이터
def generate_numbers():
for x in range(1000000):
yield x
gen = generate_numbers()
print(sys.getsizeof(gen), "bytes")
numbers = [x for x in range(1000000)]
print(sys.getsizeof(numbers), "bytes")
출력 결과
112 bytes
8448728 bytes출력결과를 보면 알 수 있듯이 Lazy Evaluation을 활용한 제너레이터는 리스트로 만든 결과와는 다르게 메모리 차이가 큽니다. 이는 Lazy Evaluation이 무한한 자료구조를 가질 수 있다는 단서가 됩니다!!
제너레이터의 동작을 보면, 제너레이터는 순차적으로 값이 필요할 때 생성하는 프로세스, 매커니즘에 가깝습니다. 그래서 다음 값이 필요할 때 값에 대한 연산을 하고 가져오기 때문에 메모리를 신경쓰지 않고 자료구조를 만들 수 있는 겁니다!
즉 정리하자면, 리스트로 만든 자료구조는 미리 100만개의 정수 자료형을 메모리에 올리는 것이고 제너레이터는 100만 개를 처리할 프로세스를 만들고 그걸 메모리에 올린 뒤 필요할 때 가져다 쓰는 방식이라고 이해하시면 됩니다.
Lazy Evaluation이 쓰이는 곳
Lazy evaluation은 다양한 컴퓨팅 분야에서 사용되며, 특히 다음과 같은 곳에서 사용됩니다!
-
함수형 프로그래밍 언어: Haskell(프로그래밍 언어)은 lazy evaluation을 기본 평가 전략으로 사용하는 가장 잘 알려진 함수형 프로그래밍 언어입니다. 여기서 lazy evaluation은 무한한 자료구조 생성, 고차원 함수 조합 등 다양한 표현력을 제공합니다.
-
스트림 처리: Java 8 이후의 Stream API나 Python의 generator와 같은 프로그래밍 언어의 특성에서 lazy evaluation이 사용됩니다. 이들은 필요할 때만 데이터를 처리하도록 설계되었습니다.
-
데이터베이스 시스템: 데이터베이스 쿼리의 최적화에서 lazy evaluation이 사용될 수 있습니다. 예를 들면, 특정 조건에 맞는 첫 번째 항목만 필요한 경우 전체 데이터셋을 스캔하지 않고, 조건을 만족하는 첫 번째 항목을 찾자마자 종료할 수 있습니다.
-
빅 데이터 처리: Apache Spark와 같은 빅 데이터 처리 프레임워크에서는 transformation 작업을 lazy하게 처리하고, 실제로 action이 호출될 때만 연산을 수행합니다. 이렇게 하면 연산의 최적화와 재사용이 가능합니다.
-
AI 및 기계 학습 프레임워크: Tensorflow나 PyTorch와 같은 딥러닝 프레임워크에서는 연산 그래프를 먼저 정의하고, 실제로 데이터가 흐를 때만 연산을 수행합니다. 이는 lazy evaluation의 일종으로 볼 수 있습니다.
-
웹 브라우저 렌더링: 웹 페이지의 컨텐츠 중 일부는 사용자가 스크롤하거나 특정 액션을 취할 때까지 로드되지 않을 수 있습니다. 이러한 “lazy loading”은 웹 페이지의 초기 로딩 시간을 단축하고 자원 사용을 최적화하는데 도움을 줍니다.
정리
이렇게 Lazy Evaluation을 알아보았는데요. 저도 이렇게 알아보면서 많이 알게되었습니다.
아무래도 대부분 프로그래밍하실 때는 Eager Evaluation을 생각하고 계실텐데요.
이렇게 Lazy Evaluation으로 동작하는 것인지, Eager Evaluation으로 동작할지 한 번씩은 고민해보는 게 좋을 것 같네요!